
قائمة المحتويات:
- تمهيد
- الطبقة التلافيفية Convolutional Layer
- خصائص إضافية في الطبقة التلافيفية
- دالة التفعيل Activation Function
- ميزات عالية المستوى
- طبقة التجميع Pooling Layer
- المصادر
أجزاء الدرس:
تمهيد:
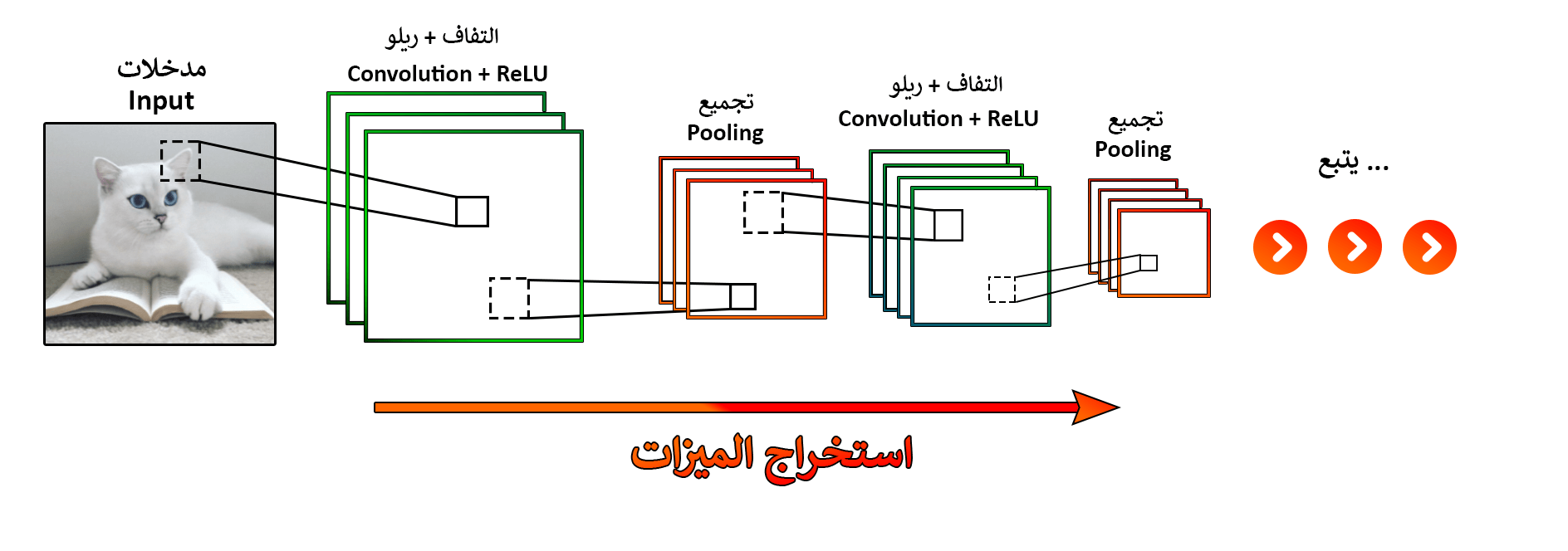
في الدرس السابق ناقشنا مفهوم الشبكات العصبية التلافيفية وأبرز العناصر المكونة لها ومدى أهميتها في مجال الرؤية المحوسبة واليوم نفتح الصندوق الأسود الخاص بها لنرى كيف تعمل من الداخل حيث أننا سنناقش في هذا الدرس طبقات الشبكة العصبية التلافيفية بأسلوب آمل أن يكون سهلاً ومبسطاً للجميع.
الطبقة التلافيفية Convolutional Layer
الطبقة الأولى في الشبكات العصبية التلافيفية هي دائماً ما تكون طبقة تلافيفية ولكن ماذا نقصد بـ تلافيفية أو تلافيف ؟! لنعد قليلاً إلى مصدر إلهام هذه الشبكات وهو الدماغ البشري للإنسان، حيث تُعد القشرة الدماغية لدينا غاية في التعقيد والسبب في ذلك احتواءها على قدر كبير من الطيات والتجاعيد والتي يطلق عليها اسم تلافيف الدماغ، هذه التلافيف مسؤولة عن توفير مساحة كبيرة من الدماغ لتكوين مليارات الخلايا العصبية (العصبونات) Neurons بالرغم من امتلاكنا جماجم صغيرة نسبياً وهذه الخلايا العصبية مسؤولة عن نقل المعلومات للخلايا العصبية الأخرى وخلايا العضلات والغدد وغيرها والتي تساعد بدورها على التعرف على الأشياء وتصنيفها من خلال نظامنا البصري، وذلك إذا ما قارنا بالكثير من الكائنات الأخرى والتي تحتوي أدمغتها على تلافيف أقل تجعلها ملساء الشكل. [2] [3] وفي المقابل فإن الطبقة التلافيفية في شبكتنا العصبية هي مسؤولة عن تكون العديد من الخلايا العصبية الاصطناعية والمساعدة في محاكاة طريقة عمل أدمغتنا.
 - الجزء الثاني 1")
ملاحظة : ذكرنا في الجزء الأول أن المدخلات إلى الشبكة العصبية التلافيفية هي عبارة عن صورة تمثل على هيئة مصفوفة من الأرقام تشير إلى عدد البكسلات ودرجة لون كل بكسل في الصورة وتكتب على سبيل المثال على النحو التالي : 32 × 32 × 3.
أحد أفضل الطرق لشرح كيفية عمل الطبقة التلافيفية هو تخيل مصباح مضيء يغطي بضوءه منطقة محددة من المدخلات (صورة القطة) ولنقل أن هذه المنطقة المضيئة تشكل 5×5 من المساحة ، هذا المصباح يلتف أو يتحرك في كل مرة وحدة إلى اليمين و تباعاً يكرر العملية ليغطي جميع مناطق الصف الأول في الصورة ، ثم يهبط بمقدار وحدة واحدة للأسفل ويكرر العملية الأولى كما هو موضح في الشكل 2.2 أدناه وهكذا إلى أن يغطي الصورة بأكملها، يطلق على هذا المصباح التخيلي في شبكتنا العصبية اسم الفلتر (المرشح) Filter أو النواة Kernel وتسمى حركة الفلتر المتتابعة بالالتفاف، ومن المهم أن يمتلك هذا الفلتر نفس عمق المدخلات أي أن يمتلك الفلتر نفس عدد القنوات الفرعية المكونة للصورة المدخلة فإما أن تكون قناة واحدة لتمثيل صور الأبيض والأسود Gray Scale أي فلتر بأبعاد 1x5x5 أو ثلاث قنوات لتمثيل الصورة الملونة RGB أي بأبعاد 3x5x5 وذلك لضمان صحة العلميات الرياضية التي سنشرحها لاحقاً في هذا الدرس، وتسمى المنطقة المضاءة من الصورة بالمجال الاستقبالي Receptive field وهي المساحة الفعالة من الصورة بسبب مرور الفلتر عليها.
 - الجزء الثاني 2")
لشرح الأمر بشكل مبسط قمنا بتحويل الصورة أعلاه إلى المقياس الرمادي Gray Scale أي إلى أبعاد 1x400x400 وذلك لتجنب استخدام القنوات الثلاث RGB للصورة ، ثم قمنا بتقليص الصورة إلى أبعاد 1x10x10 لشرح عملية التفاف الفلتر ولو دققنا بالصورة الناتجة نلاحظ أن مربعات البكسل الخاصة بالصورة أصبحت واضحة بالنسبة لنا وعددها 100 بكسل، الآن لنحاول التفكير بشكل بسيط للغاية ونقيِّم البكسلات بناء على المناطق التي تتواجد بها القطة حيث سنستخدم تمثيلاً ثنائياً 0 أو 1 وسنرمز بــ
- 0 : غياب أجزاء القطة في الصورة
- 1 : وجود أجزاء القطة في الصورة
 - الجزء الثاني 3")
 - الجزء الثاني 4")
ملاحظة: تم استخدام الفكرة أعلاه لتبسيط المفهوم ولكن بالفعل يتم وزن قيم بكسلات الصور على مقياس أكبر مثل RGB 0-255 بدلاً من 0 أو 1 وذلك للتعبير بشكل أفضل عن محتوى الصورة (تم شرح ذلك في الجزء الأول)
كما نلاحظ في الشكل 2.5 أدناه ، في كل مرة يتحرك فيها الفلتر على الصورة المصغرة ينتج قيمًا جديدة للمجال الاستقبالي الخاص بالصورة مع العلم أن الفلتر في هذه الحالة سيتموضع في 36 موضعاً مختلفاً ما ينتج عنه 36 مجالاً استقبالياً ! وكل مجال يملك أبعاد نفس أبعاد الفلتر أي 1x5x5 حيث أن أول موضع للفلتر وهو الزاوية اليسرى العليا يحتوي على القيم الموضحة في الشكل 2.6 تحت مسمى المجال الاستقبالي 1 :
 - الجزء الثاني 5")
 - الجزء الثاني 6")
في واقع الأمر فإن صورة بأبعاد 1x10x10 استخدمت لتوضيح عمل المرشح فقط حيث أنها صغيرة جداً (100 بكسل) لاستخراج ميزات عديدة ومشوهة لدرجة أنها لا تبرز أي تفاصيل لقطتنا لذا سنقوم بتكبير الصورة إلى الأبعاد الجديدة وهي 3x32x32 (1024 بكسل) وبالتالي فسيكون لدينا 784 مجالاً استقبالياً وكما هو موضح أدناه فإن ملامح القطة باتت أوضح مما سبق.
 - الجزء الثاني 7")
كما هو الحال مع المجالات الاستقبالية يمتلك الفلتر أيضاً قيماً رقمية خاصة به ، حيث يقوم الحاسب من خلال الشبكة العصبية التلافيفة بتدريب نفسه بشكل تكراري لاختيار قيم عشوائية للفلتر تسمى بالأوزان weights أو المعلمات parameters (سنشرح كيف يتم ذلك فيما الجزء الثالث)، ويقوم بتمريرها على جميع الصور المدخلة (عدة صور للقطط) لتتمكن الشبكة التلافيفية في النهاية من استخراج أنماط متكررة بسيطة في الصور يحدد من خلالها ميزات معينة للفئة المستهدفة كالأشكال الهندسية ، الحواف والمنحنيات وغيرها ، وأخيراً بعد تعديل هذه الأوزان عدة مرات يتم تثبيتها وتعيينها بشكل أساسي كقيم للفلاتر بناءً على أهمية وأولوية الميزات المكتشفة.
إذن يمكننا القول بأن هذه الفلاتر هي عبارة عن معرفات أو كواشف للميزات ! شاهد الشكل 2.8 لتكتشف كيف يتم رصد فلتر لميزة كانحناء في أذن القطة.
 - الجزء الثاني 8")
الآن ماهي الفائدة من كل من الفلتر و المجالات الاستقبالية ؟ تكمن الإجابة عن هذا السؤال فيما يسمى بخريطة الميزات (السمات) Feature Map أو خريطة التفعيل Activation map هذه الخريطة تخبرنا بأماكن وجود الميزات في صورة معينة وهي عبارة عن مصفوفة ناتجة عن ضرب كل من مصفوفة الفلتر و وجميع مصفوفات المجالات الاستقبالية بطريقة element-wise product أي ضرب العناصر المتماثلة من حيث الموقع في المصفوفتين بحيث نضرب العنصر الأول في مصفوفة الفلتر بالعنصر الأول في مصفوفة المجال الاستقبالي والعنصر الثاني في مصفوفة الفلتر في العنصر الثاني في مصفوفة المجال الاستقبالي وهكذا إلى أن نصل إلى آخر عنصر في كل من المصفوفتين ، ثم نجمع جميع نواتج الضرب ونخزنهم في قيمة واحدة كما هو موضح في الشكل 2.9 يعد الناتج “4” قيمة واحدة فقط في خريطة الميزات ولاستكمال الخريطة يجب المرور على جميع المجالات الاستقبالية:
 - الجزء الثاني 9")
خريطة الميزات (السمات) = مجموع [مصفوفة المجال الاستقبالي لكل موضع للفلتر X مصفوفة أوزان الفلتر]
 - الجزء الثاني 10")
الآن سنستخدم الفلتر الكاشف لميزة الإنحناء في أذن القطة ونطبقه على جزء صغير من صورة أخرى لقطة لاستخراج خريطة الميزات، وكما تشاهد في الشكل 2.9 فقد قمنا بإعادة وزن الميزات الخاصة بصورة القطة البيضاء ليكون المثال أكثر واقعية إلى حد ما بحيث أن الإنحناء في الأذن يشكل 50 نقطة ولون الأذن الداخلي يشكل 15 نقطة ولون القطة 5 نقاط وهكذا إلى أن تكتمل الصورة ولكن في الواقع يتم وزن الصور بناء على مقياس RGB أي شدة لون كل بكسل وقد تم ذلك لتوضيح طريقة عمل خريطة الميزات وحسب.
 - الجزء الثاني 11")
شاهد كيف يتم تشكيل خريطة الميزات الخاصة بالصورة عن طريق ضرب الفلتر بالمجالات الاستقبالية بطريقة element-wise product ، ونلاحظ أن أصغر قيمة مثلت الميزة الموجودة بالفلتر (وجود إنحناء في صورة القطة البيضاء) كانت للمجال الاستقبالي الأول بـ 20 نقطة بينما أكبر قيمة كانت للمجال الاستقبالي السادس بـ 255 نقطة فبناءً على هذه القيم يتم تحديد ما إذا كانت هنالك الميزة المطلوبة (منحنى الأذن) في الصورة أما لا !.
 - الجزء الثاني 12")
 - الجزء الثاني 13")
0x0 + 0x0 + 0x0 + 0x1 + 0x1 + 0x0 + 0x0 + 0x1 + 0x0 + 0x1 + 0x0 + 0x1 + 0x0 + 0x0 +50x0 + 20x1 +20x0 +20x0 + 50x0 + 15x0 + 5x0 + 5x0 + 5x0 + 5x0 +15x0 = 20
 - الجزء الثاني 14")
0x0 + 0x0 + 0x0 + 50x1 + 50x1 + 0x0 + 0x0 + 50x1 + 15x0 + 50x1 + 20x0 + 50x1 + 15x0 + 15x0 +10x0 + 5x1 +5x0 +15x0 +15x0 + 0x0 + 5x0 + 5x0 + 5x0 + 5x0 + 0x0 = 255
الفلتر الذي استخدم في هذا الجزء كان مبسطاً لغرض رئيسي وهو تبسيط الرياضيات التي تجري أثناء التفاف الفلتر على الصورة ،في الشكل 2.13 مجموعة من الفلاتر المشهورة مع أوزانها الخاصة و مخرجاتها.
 - الجزء الثاني 15")
في الصورة المتحركة أدناه سترى بعض الأمثلة على العمليات الفعلية حيث يتم استخدام فلتر أساسي متفرع منه ثلاث فلاتر لقنوات RGB (يعتبر فلتراً واحداً في نهاية المطاف )ومع ذلك ، يبقى الأمر كما هو حيث تلتف هذه الفلاتر الفرعية حول صورة مدخلة و “تنشط” (أو تحسب القيم العليا ) عندما تكون الميزة المحددة التي تبحث عنها موجودة في الصورة المدخلة .
 - الجزء الثاني 16")
 - الجزء الثاني 17")
خصائص إضافية في الطبقة التلافيفية:
كما أشرنا سابقاً فبعد أن تقوم باختيار أبعاد الفلتر فإن الشبكة التلافيفية تقوم بوزن قيم الفلاتر بشكل تكراري إلى أن تصل إلى قيم تمثل ميزات فارقة في الصور لتتمكن من تصنيف الصور بناءً عليها ، وكل هذه العمليات تحدث دون تدخل مباشر من الشخص القائم على تدريب نموذج التصنيف ولكن هنالك بعض المعاملات Parameters يجب تحديدها في الطبقة التلافيفية تساهم بشكل أساسي بجودة مخرجاتها وهي كالتالي:
1- العمق Depth : تحدثنا في هذا الدرس عن مفهوم العمق الخاص بالفلتر وأنه يشير إلى قنوات RGB الثلاثة ولكن مانريد تسليط الضوء عليه الآن هو عمق مجموعة خرائط الميزات (الطبقة التلافيفية) وكما أشرنا سابقاً فإن كل فلتر قادر على إنتاج خريطة ميزات Feature map واحدة ولكن هب أن لدينا عدة فلاتر يحمل كل منها ميزة مختلفة سيتغير الأمر وسيكون لدينا طبقة تلافيفية بعمق عدد تلك الفلاتر.
مثال توضيحي: إذا كان لدينا صورة بأبعاد 3x32x32 و 6 فلاتر بأبعاد 3x5x5 فهذا يقتضي مجموعة من خرائط الميزات (طبقة تلافيفية) بأبعاد 6x28x28 تحتوي على ست خرائط كل منها بأبعاد 1x28x28 شاهد الشكل 2.15 لتضح الصورة بالنسبة لك.
 - الجزء الثاني 18")
الشكل 2.15 : تكوين الطبقة التلافيفية باستخدام عدة خرائط ميزات وعدة فلاتر
2- الخطوة التمريرية Stride: ويقصد بها مقدار الحركة التي يتحرك بها الفلتر خلال مروره على الصورة وتقاس بالبكسل ، فعندما يكون مقدار الخطوة التمريرية يساوي 1 يتحرك (يلتف) الفلتر بكسل واحد في كل مرة وعندما يكون المقدار يساوي 2 يتحرك بكسلين في كل مرة وهكذا…. شاهد الصورة التوضيحة أدناه ولاحظ أن مقدار الخطوة التمريرية يؤثر على حجم خريطة الميزات الناتجة.
 - الجزء الثاني 19")
3- التبطين الصفري Zero-padding: لو دققنا الملاحظة في عملية الالتفاف أعلاه لوجدنا مشكلة تكمن في عدم القدرة على تغطية بعض المناطق بالصورة في حال زيادة مقدار الخطوة التمريرية ولحل هذه المشكلة يتم استخدام أسلوب يدعى بالتبطين الصفري Zero-padding وهو عملية إضافة أصفار حول الصورة للتحكم بشكل أفضل بعملية الالتفاف وبالتالي زيادة حجم خريطة الميزات ويسمى هذا الأسلوب أيضاً بالالتفاف العريض wide convolution بينما طريقة الالتفاف بشكل تقليدي فتسمى بالالتفاف الضيق narrow convolution
 - الجزء الثاني 20")
دالة التفعيل Activation Function:
هي دالة لا خطية تعتبر جسر العبور إلى الطبقة التالية في الشبكة العصبية التلافيفية و تكمن فائدتها في تقليل كمية الحسابات المنجزة من خلال عدم تفعيل جميع نقاط خرائط الميزات في آن واحد، و بمعنى أدق تفعيل النقاط التي تمثل الميزات وإقصاء النقاط التي لا تمثلها ، ولها عدة أنواع أشهرها:
- Sigmoid
- TanH
- ReLU
سنناقش في هذا الدرس الدالة الأكثر فعالية بينها والمسماة بالريلو ReLU أو الوحدة الخطية المصححة Rectified Linear Unit
 - الجزء الثاني 21")
طريقة عمل دالة التفعيل ReLU عندما تكون قيمة x سالبة فإن النتيجة f(x) = 0 بينما عندما تكون قيمة x موجبة فتكون f(x) = x أي نأخذ القيمة نفسها انظر الشكل 2.18
يتم تقليل الحسابات من خلال تصفير القيم السالبة في كل خريطة ميزات وإبقاء القيم الموجبة كما هي، حيث أشرنا سابقاً أن القيم السالبة في خريطة الميزات لأي فلتر لا تمثل الميزة المطلوب البحث عنها في الصورة إطلاقاً ولذلك دعت الحاجة لإقصائها لتوفير القدرة الحاسوبية !
 - الجزء الثاني 22")
ميزات عالية المستوى:
دعونا نرجع خطوة إلى الوراء ونراجع ما تعلمناه حتى الآن، تحدثنا عن الفلاتر في الطبقة التلافيفية الأولى و الهدف من تصميمها وطريقة عملها لاستخلاص خرائط الميزات كما تطرقنا إلى الأساليب المتبعة في تحسينها، حيث أن هذه الفلاتر تقوم بالكشف عن ميزات منخفضة المستوى مثل الحواف والمنحنيات ، وذلك من أجل التنبؤ بما إذا كانت الصورة هي أحد الأنواع التي نستهدف تصنيفها ، ولكن نحتاج من الشبكة التلافيفية أن تكون قادرة على التعرف على ميزات بمستويات أعلى مثل اليدين ، العينين أو الأذنين. لذلك دعونا نفكر في ناتج مدخلات الشبكة بعد مرورها بالطبقة التلافيفية الأولى والذي سيكون بأبعاد 6x28x28 (على افتراض أننا نستخدم 6 فلاتر بأبعاد 3x5x5).
عندما يمر هذا الناتج عبر طبقة تلافيفية أخرى يصبح ناتج الطبقة الأولى (خرائط الميزات المصححة) هو مدخلات الطبقة التلافيفية الثانية وهذا أصعب قليلاً في التصور فعندما كنا نتحدث عن الطبقة الأولى كان الإدخال هو الصورة الأصلية فقط بينما مدخلات الطبقة الثانية ستكون خرائط الميزات التي تنتج من الطبقة الأولى.
إذن فإن كل طبقة من المدخلات تصف بشكل أساسي مواقع في الصورة الأصلية تظهر بعض الميزات ذات المستوى المنخفض (منحنيات ، قطع مستقيمة ، حواف)، و عندما نقوم بتطبيق مجموعة من الفلاتر فوق هذه الخرائط (نقوم بتمريرها عبر الطبقة الثانية) ، سيكون الناتج عبارة عن عمليات تنشيط تمثل ميزات ذات مستوى أعلى يمكن أن تكون أنواع هذه الميزات أنصاف دوائر (مزيج من منحنى وحافة مستقيمة) أو مربعات (مزيج من عدة حواف مستقيمة)، وأثناء تنقلك عبر الشبكة وتصفح المزيد من الطبقات التلافيفية ، ستحصل على خرائط ميزات تمثل المزيد والمزيد من الميزات المعقدة ، وبنهاية الشبكة ، قد يكون لديك بعض الفلاتر التي يتم تنشيطها عندما يكون هنالك يد أو عين أو حتى وجه بأكمله. [4]
 - الجزء الثاني 24")
إذا أردت معرفة كيف يتم تصوير تلك الفلاتر أنصحك بقراءة هذه الورقة البحثية ومشاهدة هذا الفيديو على YouTube. شيء آخر مثير للاهتمام يجب ملاحظته هو أنه كلما تعمقت في الشبكة التلافيفية ، تبدأ الفلاتر في الحصول على مجالات استقبالية أكبر وأكبر ، مما يعني أنها قادرة على النظر في المعلومات في مساحة أكبر من حجم المدخلات الأصلي (الصور).
طبقة التجميع Pooling Layer:
بعد إنشاء الطبقات التلافيفية Convolution Layers وتطبيق دوال التفعيل عليها كدالة ReLU يتم استخدام أسلوب يسمى بالتجميع المكاني Spatial Pooling يطلق عليه أيضاً عملية الاختزال downsampling أو جمع العينات subsampling.
يهدف هذا الأسلوب إلى تقليل أبعاد خريطة الميزات المصححة و استخلاص أهم المعلومات في الصور (الميزات) وكما هو الحال مع دالة التفعيل يوجد عدة خيارات من الممكن تطبقيها في طبقة التجميع أشهرها التجميع الأقصى maxpooling حيث يتم بالعادة تخصيص فلتر بأبعاد 2×2 و خطوة تمريرية = 2 بكسل ويتم تطبقيها على خرائط الميزات حيث يقوم الفلتر باستخراج القيمة العظمى ضمن كل مساحة فعالة بواسطته كما هو موضح في الشكل 2.21 أدناه.
 - الجزء الثاني 25")
يوجد خيار آخر مشهور يسمى بالتجميع بأسلوب المتسوط الحسابي AveragePooling حيث يتم جمع القيم الموجود ضمن حدود الفلتر وقسمتها على عدد هذه القيم.
والمنطق وراء هذه الطبقة هو أنه بمجرد أن نعلم أن ميزة معينة موجودة في أبعاد المدخلات الأصلية (ستكون هناك قيمة تنشيط عالية) ، فإن موقعها الدقيق ليس بنفس أهمية موقعها النسبي بالنسبة إلى الميزات الأخرى ، وعلاوة على ذلك تقلل هذه الطبقة بشكل كبير من أبعاد حجم مدخلات خرائط الميزات إلى الطبقات الأخرى حيث يتغير الطول والعرض فقط وليس العمق وهذا يخدم غرضين رئيسيين:
الأول هو أن مقدار المعلمات أو الأوزان يتم تقليله بنسبة 75% ، وبالتالي تقليل كمية الحسابات غير الضرورية.
والثاني هو أنه سيتحكم في مشكلة فرط التدريب Overfitting و يشير هذا المصطلح إلى تفوق النموذج في تصنيف بيانات التدريب وعدم قدرته على تعميم نتائجه بشكل جيد على بيانات لم يرها مسبقاً فعلى سبيل المثال قد يحصل النموذج على نسبة 100% أو 99% من الدقة على مجموعة التدريب (مجموعة القطط التي تدرب على تصنيفها) بينما يفشل في التعرف على بيانات الاختبار (صور لقطط لم يتم يتدرب عليها النموذج) ويحصل على دقة تساوي 50% والتي تعتبر دقة سيئة جداً لنموذج ذكاء اصطناعي!
المصادر:
[1] A Beginner’s Guide To Understanding Convolutional Neural Networks,
[2] Why Do Our Brains Have Folds?,” LiveScience
[3] How the Human Brain Gets Its Wrinkles LiveScience
[4] Visualizing and Understanding Convolutional Networks, Matthew D. Zeiler and Rob Fergus
[5] Convolutional Neural Networks, Medium
[6] CS231n Convolutional Neural Networks for Visual Recognition
[7] الشبكات العصبية الترشيحية CNNs
[8] An Intuitive Explanation of Convolutional Neural Networks










بارك الله فيكم
شرح واضح ومفيد لكل مبتدئ
جزاك الله خير